
Schedule a demo with us
We can help you solve company communication.
Adapting neural networks to complex, changing visual conditions, with minimal supervision.
Our project builds upon exisitng state-of-the-art models on semantic segmentation (pixel-labeling), a critical task for autonomous driving.
Our project generalizes neural networks trained on well-labeled source domains, to unlabeled, continously changing target domains.
Our algorithms help neural networks identify the most informative unseen target samples and adapts to new conditions in real-time.
Neural networks can achieve state-of-the-art performance on computer vision tasks with ample training data. However, in real-world scenarios, labeled data for training is often limited and expensive to obtain. The environments in which models are deployed can evolve in unexpected ways.


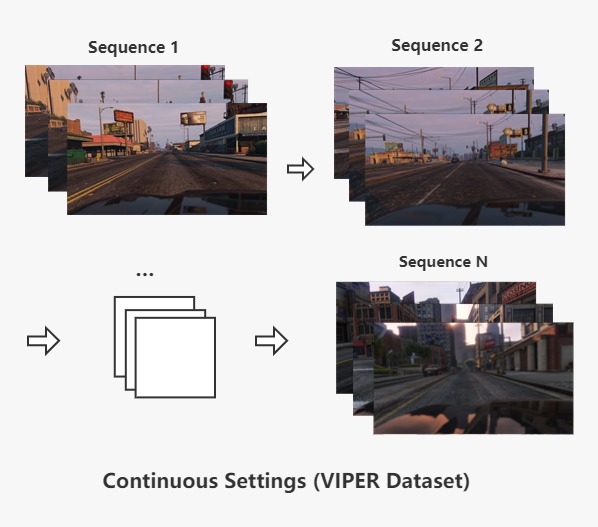
The target domains are urban street view datasets containing real-world images and continously changing visual features: CITYPSCAPES and VIPER. To perform semantic segmentation on these targets, networks need to adapt to these more realistic, and continously changing conditions.
Our project has two sub-routines. First, we design the active sample selection strategies that yield the most informative, diverse and representative data points from the unseen target. Second, we research on the continous adaptation approaches that best accumulate past knowledge. We then combine our finding into the novel method, ACCDA, which actively selects samples and learns on the fly.
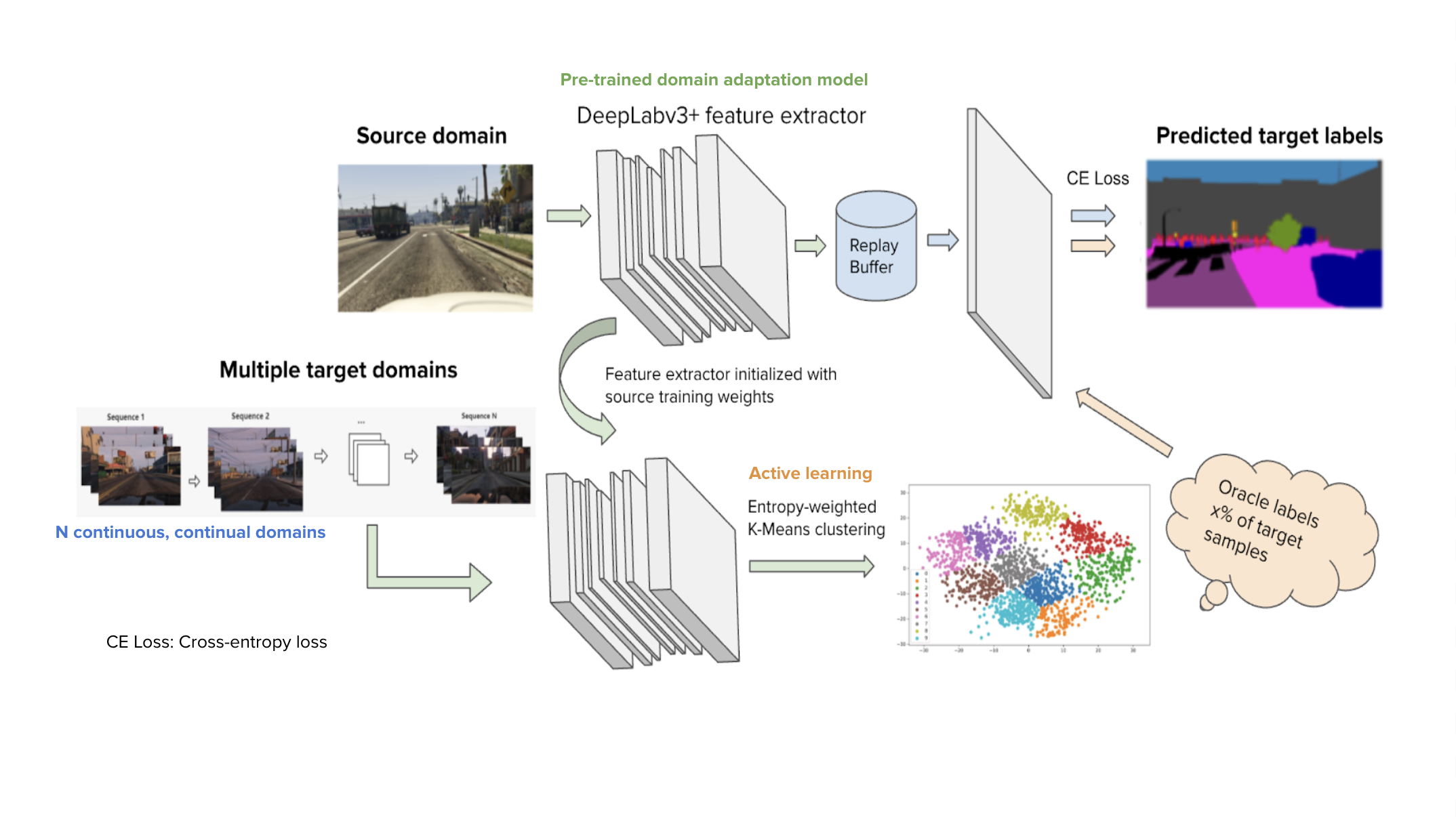
ACCDA performs adversarial learning on the source samples for semantic segmentation, by minimizing cross-entropy loss. The backbone model is VGG16-Deeplab-v3.
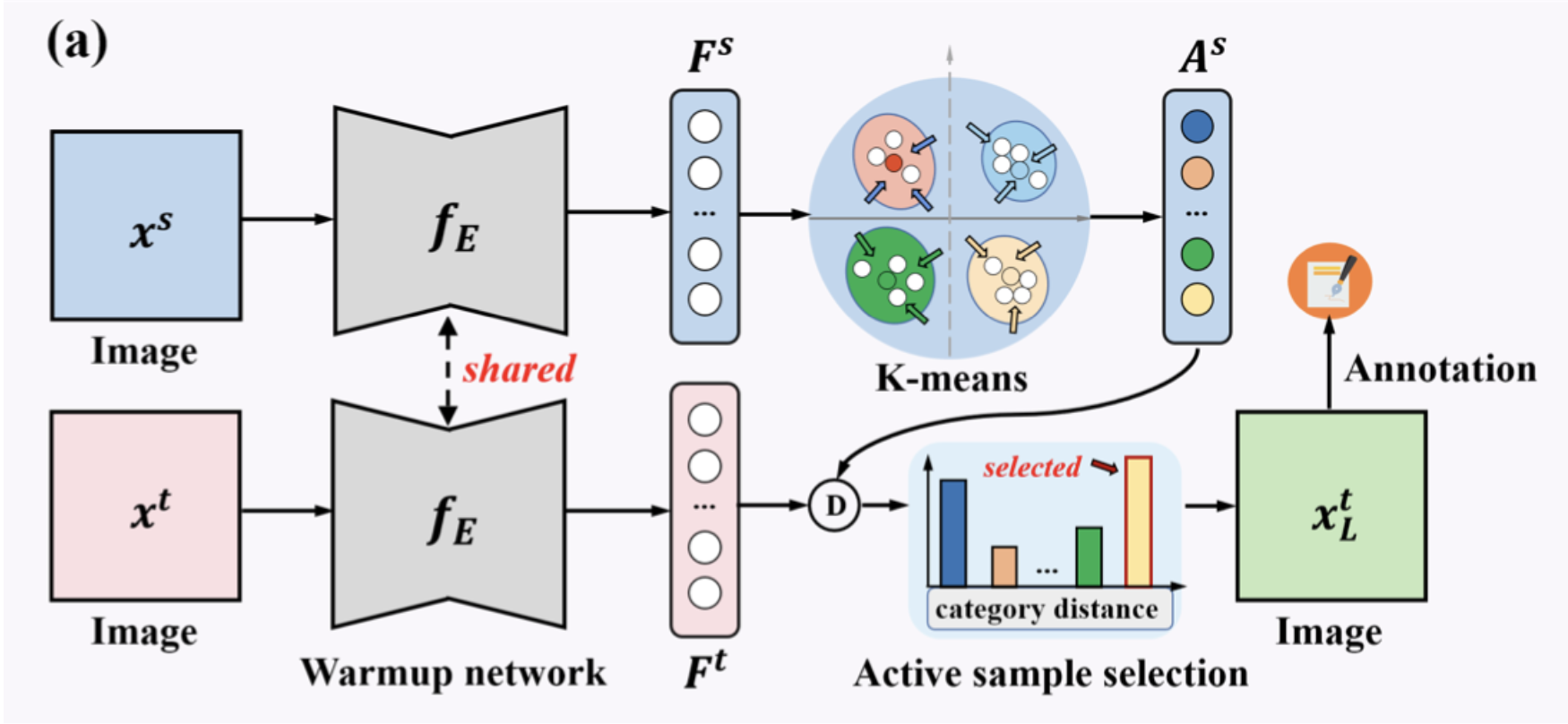
ACCDA then uses our novel entropy-weighted multi-anchor stragety to select a few number of informative and diverse unseen samples from target to acquire label and learn to adapt.
ACCDA adapts to continously shifting target frames with our designed replay buffer, which remembers previously-seen domain information.
Multi-anchor. Our algorithm groups the source features into clusters and treat their centroids as anchors. It then computes the distance between target samples to the source anchors.
Entropy. The anchor distance is then weighted by entropy to better capture the samples' informativeness. Target samples that are closest to source anchors and have high entropy are then selected.
Sequential adaptation. We explored adaptation schemas that sequentially adapt a segmentation model to multiple gradually changing target frames. At each iteration, the current segmentation model will be adapted to the next target frame.
Replay buffer. We designed a novel replay buffer that accumulates previously-seen knowledge and improve network performance in continously shifting visual frames.
The baseline AdaptSegNet model and our customized continous contiual segmentation model only achieve around 25% mIoU on target domain without adaptation. After adaptation with our designed replay buffer, we boosts the target domain performance to around 41% mIoU. Then by integrating our novel entropy-weighted mutli-anchor active learning strategy, we pushes the performance further to be above 58% mIoU.
Baseline (w/o adaptation)
Continous DA (w/o adaptation)
Continous DA (w/ adaptation + replay)
ACCDA (replay buffer + entropy multi-anchor)
The backbone network is able to achieve better and better performance on target domain, by utilizing active learning and continual, continous adaptation.



